AMD首款符合Ultra Ethernet规范400GbE网卡进入部署阶段,性能超群,市场期待高
更新时间:2025-06-13 19:35:05作者:fs0745
6 月 13 日消息,AMD 在今年 4 月推出了 Pensando Pollara 400 NIC 网口,这也是首款兼容 Ultra Ethernet Consortium(注:即超以太网联盟 UEC)规范的 400GbE 网卡产品。
在今日的“Advancing AI”活动中,AMD 宣布 Pensando Pollara 已进入部署阶段。同期,UEC 联盟发布面向超大规模 AI 与 HPC 数据中心的技术规范 1.0 版本,该技术生态正式迈入落地阶段。

AMD 表示,甲骨文(Oracle)云基础设施(OCI)成为首批部署该网卡的超大规模云服务商,其还将同步采用 AMD Instinct MI350X 系列 GPU。
按规划,这些硬件今年下半年起在 OCI 大规模落地,Oracle 拟以此构建规模达 131,072 块 Instinct MI355X 的泽字节级 AI 集群,支撑客户开展大规模 AI 训练与推理。

据介绍,Pensando Pollara 400GbE 网卡专为超大规模场景(支持百万级 AI 处理器或 GPU 互联)设计,核心亮点包括:
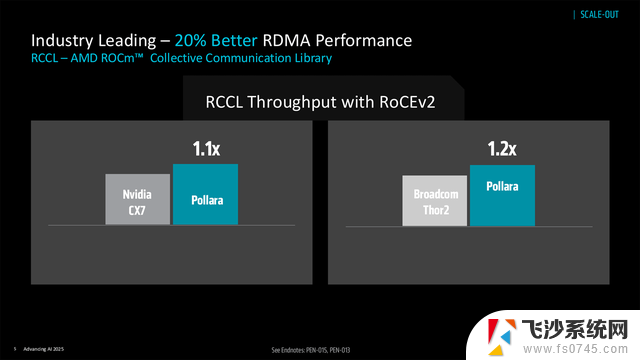
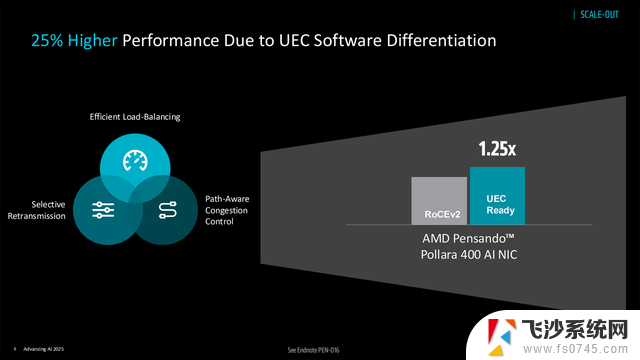
性能表现:RDMA 性能较 NVIDIA CX7 高 10%、较 Broadcom Thor2 高 20%;结合 Ultra Ethernet 1.0 规范的智能负载均衡、选择性重传、路径感知拥塞控制,RDMA 性能较传统 RoCEv2 再提升 25%,AI 负载处理效率最高达 6 倍提升。
智能调度:基于自研专用处理器与可定制硬件,实现数据流智能拆分与动态路由,规避网络瓶颈,保障大规模 GPU 集群吞吐量稳定。
高可靠性:搭载故障转移技术,可快速检测并绕开故障连接,在数万加速器互联场景下维持低延迟与高集群利用率。
AMD 表示,除甲骨文外,其他规划大规模 Instinct GPU 部署的企业也将快速跟进,推动 Ultra Ethernet 硬件生态普及。目前该网卡已向意向客户启动交付。