刚刚,英伟达发布新规:其他硬件禁止使用CUDA!- 重大变革影响深远!
英伟达终于对竞争者下了死手!
在安装CUDA 11.6及更高版本时,最终用户许可协议(EULA)中明确表示:禁止在其他硬件平台上通过翻译层运行基于CUDA的软件!
英伟达这个意义明显的举动马上引起了各大媒体的关注:
事实上,自2021年起,英伟达在网上发布的许可条款中就有关于CUDA的这项警告,但它从未出现在安装过程中提供的文档里。
而今,英伟达摊牌了、不装了,明确表示,护城河是我的,AI计算的果子是我的!
某些友商啊,不要耍一些小聪明,在自家的硬件上用我的CUDA。
对此,我们首先想到的可能就是像ZLUDA这样的项目,能够让Intel和AMD的GPU,无需修改即可运行CUDA应用程序。
对于这样的项目,以及表现出的性能,个人开发者是惊讶的,而英伟达更是震惊的。
2月18号,软件工程师Longhorn在推上表示自己发现了CUDA新增的条款:
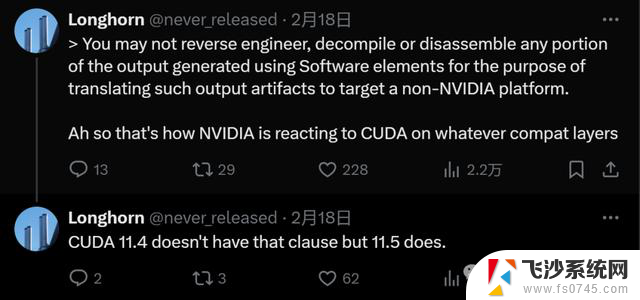
也就是下面英伟达提供的官方条款的最后一条:
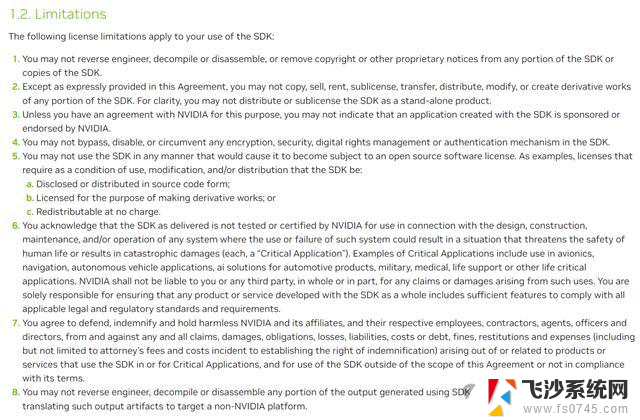
这一条款在CUDA 11.4和11.5版本的安装文档中是没有的,可以推测之前的所有版本中也没有,应该是从11.6版本开始新加的。
当然了,作为行业领导者,英伟达也有自己的难处。
一方面,大家都依赖你;另一方面,每个人都想利用你的成就。
CUDA就是一个例子——由于它与英伟达GPU搭配使用非常高效,因此备受相关应用开发者的青睐;但随着更有性价比的硬件层出不穷,越来越多的用户倾向于在其他平台上运行CUDA程序。
目前,有两种方法可以实现:重新编译代码(适用于相应程序的开发者)或使用翻译层。
使用像ZLUDA这样的翻译层是在非英伟达硬件上运行CUDA程序最简单的方式——只需使用已编译的二进制文件,通过ZLUDA或其他翻译层运行即可。
尽管ZLUDA目前遇到了困难,AMD和Intel已经放弃了进一步开发的机会,但这并不意味着翻译层不再是一个可行的方案。
显然,使用翻译层挑战了英伟达在加速计算领域,特别是AI应用中的主导地位。这可能是英伟达决定禁止在其他硬件平台上使用翻译层运行其CUDA应用程序的主要原因。

不过,重新编译现有的CUDA程序仍然是合法的。为了简化这一过程,AMD和Intel分别提供了将CUDA程序移植到他们的ROCm和OpenAPI平台的工具。
随着AMD、Intel等公司开发出更好的硬件,更多的软件开发者将倾向于为这些平台设计,而英伟达在CUDA领域的主导地位可能会逐渐减弱。
此外,专门为特定处理器开发和编译的程序肯定会比通过翻译层运行的软件表现得更好,这意味着其他公司将在与英伟达的竞争中占据更有利的位置——如果他们能够吸引软件开发者的话。
CUDA
说了这么多,CUDA到底有什么神奇的作用,让大家趋之若鹜?
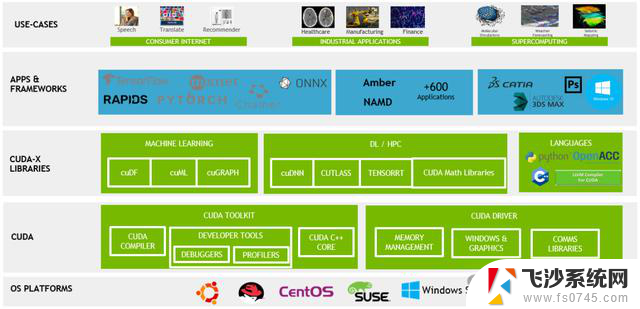
CUDA的全称是计算统一设备架构(Compute Unified Device Architecture),是英伟达开发的一种异构编程语言。它为通用程序提供了调用GPU的接口。
异构编程的意思是分开编写CPU和GPU的代码,各自负责自己有利的部分(比如CPU的逻辑控制能力和GPU的并行计算能力)。
而且,通过英伟达自己的不断优化,可以最大限度利用GPU的优势,这一点对自己很重要,对用户也很重要。

CUDA基于C和C++,允许开发人员控制计算的分配,充分利用GPU的多线程能力来加速计算任务。
开发人员可以将程序划分为可独立执行的子任务,分给GPU的不同线程,显著提高了程序的性能。
世界各地的公司都在日常运营中采用了CUDA,并产生了巨大的收益。
例如,特斯拉和其他汽车行业巨头利用CUDA来训练自动驾驶汽车;Netflix在GPU上运行自己的神经网络模型,利用CUDA的功能来增强自己的推荐引擎。

为什么这些大型科技公司不约而同地选择了CUDA,而不是其他的方法?
答案是速度。CUDA加快了神经网络模型的预测速度,快速给出输出结果,满足了企业和产品对快速执行的需求。
除了速度之外,CUDA还提供可扩展性,可以毫不费力地处理大量数据,以执行实时、高需求的任务。
从本质上讲,是否使用CUDA取决于任务的需求。对于较轻的工作负载,可以选择不同的方法。
然而,当涉及到生产级性能和实时输出需求时,CUDA仍然是大公司的首选解决方案,将大型模型转换为无缝、高效的体验。
如果不使用CUDA,处理时间会慢多少?
以Netflix为例,他们的NRE(Netflix的推荐引擎)模型的训练,一开始需要花费20多个小时,
然而,通过利用CUDA内核的优化,这个时间大大缩短到47分钟。
这也正是利用GPU的大公司选择CUDA来增强其应用程序的原因。

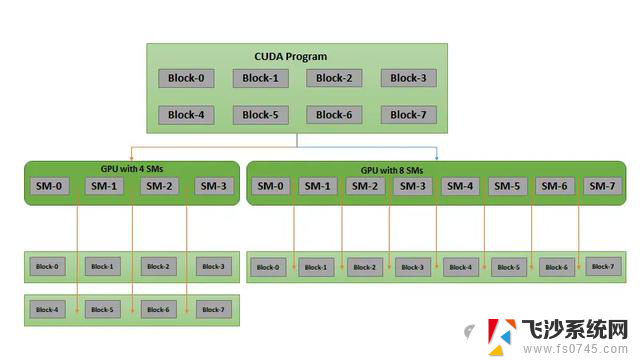
CUDA 编程模型基于网格、块和线程(grids, blocks, and threads)的概念。
网格是块的集合,块是线程的集合。每个线程都有一个唯一的标识符,用于确定它正在执行的数据。
每个英伟达显卡都有一定数量的内核,内核决定了GPU的功率和处理速度。

内核数量越多,意味着我们可以并行处理的数据越多。
将任务划分为更小的计算,分配给线程来执行操作,并且使用同步块组合来获得最终结果,这相比于CPU可以达到至少50倍的加速。
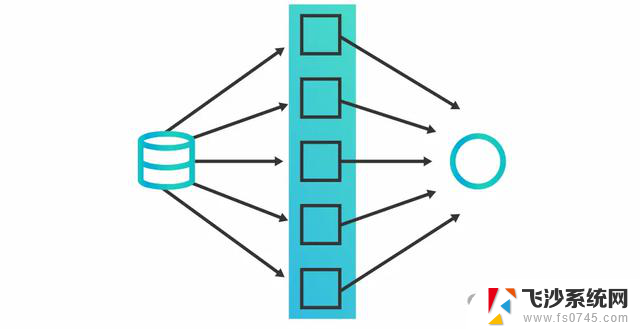
我们当前使用的神经网络正是并行计算的代表,因为每个节点的计算通常独立于所有其他节点,可以很容易地应用于GPU。
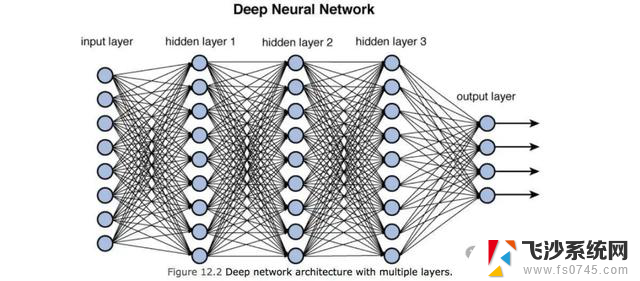
借助CUDA,可以开发在GPU上运行的,数千或数十万个并行线程加速的高性能算法。
CUDA遵循以下原则:并行性、计算、同步。
cuDNN(CUDA Deep Neural Networks)是一个GPU加速库,彻底改变了深度学习框架的世界。它与PyTorch、TensorFlow、MxNet、Caffe2等兼容,是增强这些框架性能的基石。
cuDNN拥有对基本操作的微调实现,包括前向和后向卷积、池化、归一化和激活层。它的真正实力在于能够快速执行通用矩阵乘法(GEMM),同时节省宝贵的内存资源,这是传统方法难以实现的壮举。
大型语言和计算机视觉模型,严重依赖CUDA和cuDNN进行GPU加速。从本质上讲,CUDA和cuDNN是推动下一代深度学习模型的催化剂。
ZLUDA
上文提到的ZLUDA,能够让Intel和AMD的GPU,无需修改即可运行CUDA应用程序,并且运行性能接近原生。
用法也很简单,只用像往常一样运行程序,同时确保已加载替换CUDA的ZLUDA库即可。
项目地址:https://github.com/vosen/ZLUDA?tab=readme-ov-file#faq
目前ZLUDA还处于alpha版本,但它已经被证实能够支持多种原生CUDA应用程序。如Geekbench、3DF Zephyr、Blender、Reality Capture、LAMMPS、NAMD、waifu2x、OpenFOAM、Arnold(概念验证)等。
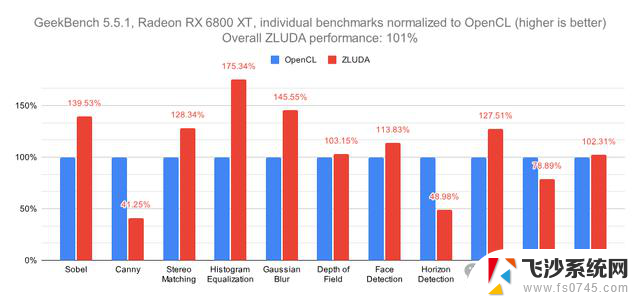
软件工程师Michael Larabel在经过几天的试用之后表示:支持CUDA的软件确实能够在ROCm上无缝运行,即便是专有渲染器等也能够配合这种「Radeon版CUDA」实现工作。
不过,ZLUDA也有一些缺陷,例如它还不完全支持英伟达OptiX,同时也还没能处理不使用PTX汇编代码的软件。
但总体而言,考虑到这是一位独立开发者的成果,这种实现的能力还是相当出色的。
网友热议
对于英伟达这个看上去有点严重的警告,网友们众说纷纭。
这位网友表示:在Java/Android诉讼中已经确定,API不能受版权保护。一些司法管辖区甚至明确允许出于互操作性的目的进行逆向工程。

「这意味着,英伟达在EULA中的警告条款,不会使ZLUDA或任何其他不包含英伟达代码的解决方案成为非法使用。」
但另一位网友回应道,「我认为这不适用于这种特殊情况。我调查了一下,似乎裁决是针对不能受版权保护的概念,而不是实际的API本身。」
「Google基于概念创建了自己的API,这与创建翻译层以利用英伟达现有的API不同。」
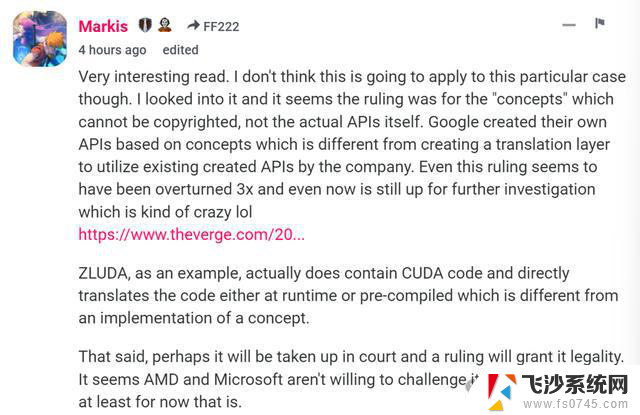
「例如,ZLUDA实际上确实包含CUDA代码,并在运行时或预编译时直接翻译代码,这与概念的实现不同。」
「也就是说,法庭的裁决会倾向于英伟达。AMD和微软似乎不愿意挑战它,至少目前是这样。」
说到打官司,网友表示:这不就是任天堂嘛!
「被英伟达起诉绝对不是什么好事」。

有网友认为,现在唯一的问题是,许多应用程序都与CUDA完全绑定,别无选择。

当然了,这还要看英伟达到底怎么想的,「这完全取决于公司的心态。例如,微软让破解的Windows永远存在。」
网友表示,「英伟达希望保护自己的知识产权,并将客户与他们的生态系统联系起来,这是一个有利于企业本身的商业决策。这是可以理解的。」