Dynamo 0.4最新版本:四倍性能提升、SLO自动扩展和实时可观察性
Dynamo 0.4 的主要亮点包括:
提供针对 NVIDIA 高性能计算平台的大规模专家并行部署指南
新的 prefill-decode (PD) 配置工具,简化 PD 分离架构设置
支持基于 SLO 的 PD 自动扩展,并集成 Kubernetes
内置可观察性指标,支持实时性能监测
通过实时请求重定向和早期故障检测提升系统韧性
通过下文了解更多关于这些更新的信息。
Dynamo 0.4 如何通过
PD 分离将推理性能提高至 4 倍
Dynamo 0.4 大幅提升了 NVIDIA Blackwell 上的 PD 分离服务性能。在 NVIDIA Blackwell 架构 GPU 上使用 Dynamo 和 TensorRT-LLM 运行新的 OpenAI gpt-oss-120b 模型,能够在不降低吞吐量的情况下,将长输入序列(常见于智能体工作流、代码生成和摘要任务)场景下的交互速度(Token / 秒 / 用户)至高提速 4 倍。
此外,在 NVIDIA 高性能计算平台上基于 TensorRT-LLM 和 Dynamo 运行 DeepSeek-R1 671B 模型,能够在不增加推理成本的情况下,将吞吐量(Token / 秒 / GPU)提升 2.5 倍。
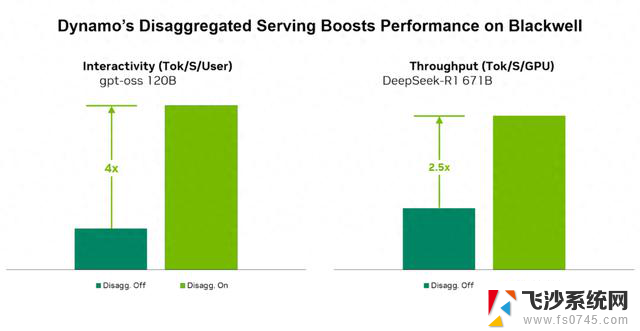
图 1. PD 分离服务解决了 prefill 与 decode 之间的资源竞争问题,能够在不增加 GPU 预算的情况下显著提升性能。
(注:图中结果仅供技术探讨和参考,并且不代表最大吞吐量或最小延迟性能。复制此链接至浏览器查看最新推理性能:https://developer.nvidia.com/deep-learning-performance-training-inference/ai-inference)
图中的性能提升来源于使用 Dynamo 进行的 PD 分离服务,该架构将模型推理的 prefill 和 decode 阶段分离到独立的 GPU 上。通过分离这两个阶段,Dynamo 能够根据每个阶段的具体需求灵活分配 GPU 资源和模型并行策略,从而大幅提高整体效率。
我们十分高兴能够发布这些脚本,使社区能够复现这些结果并充分发挥 PD 分离服务架构的成本效益。参见以下 GitHub 链接:
https://github.com/ai-dynamo/dynamo/blob/main/components/backends/trtllm/gpt-oss.md
https://github.com/ai-dynamo/dynamo/tree/main/components/backends/trtllm/performance_sweeps
为了帮助研究者、工程师和企业探索 PD 分离服务架构下的 MoE 模型部署优势,我们还提供了详尽的部署指南。分步指导用户在多节点环境中使用 Dynamo 部署 DeepSeek-R1 (结合 SGLang) 和 Llama4 Maverick (结合 TensorRT-LLM)。参见以下 GitHub 链接:
https://github.com/ai-dynamo/dynamo/blob/main/components/backends/sglang/docs/dsr1-wideep-gb200.md
https://github.com/ai-dynamo/dynamo/blob/main/components/backends/sglang/docs/dsr1-wideep-h100.md
https://github.com/ai-dynamo/dynamo/blob/main/components/backends/trtllm/llama4_plus_eagle.md
如何简化消除 PD 分离最佳配置的
大量猜测和试错的工作
我们从采用 PD 分离服务的推理团队了解的主要挑战之一,是如何估算预期吞吐量收益,并确定适合其特定部署的正确配置。具体而言,用户反馈难以决定分配 prefill 和 decode 阶段的 GPU 数量,以及在满足目标 SLO 前提下,如何选择模型并行策略。
为此,我们推出 AIConfigurator,这是一个专为推荐最佳 PD 分离配置和模型并行策略设计的新工具,根据特定模型和 GPU 预算满足 SLO 要求。
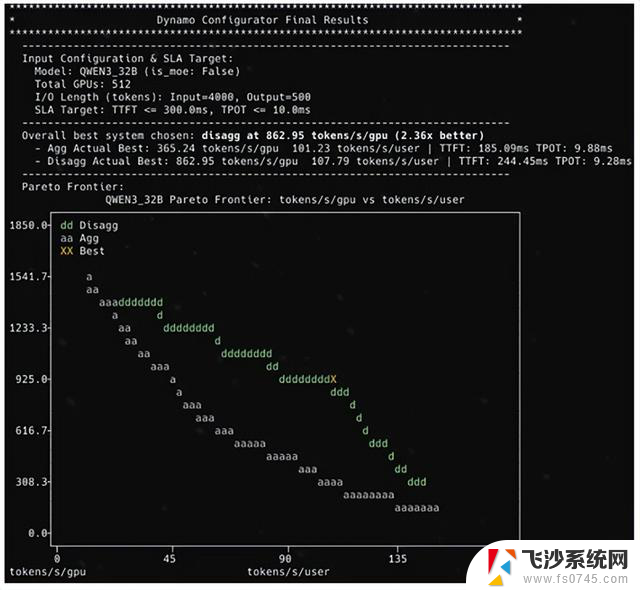
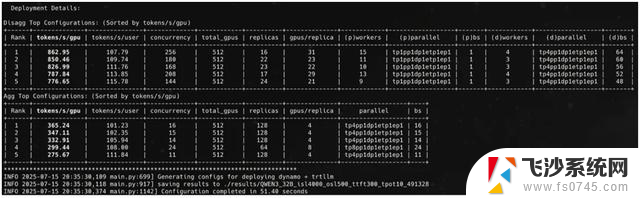
图 2. AIConfigurator CLI 控制面板的截图,它可视化了吞吐量与延迟间的权衡及 PD 分离的收益。在相似的延迟水平下,使用 PD 分离架构将 Qwen3-32B 模型部署在 512 个 GPU 组成的集群中,可使吞吐量提高至 2.36 倍。
AIConfigurator 利用大量离线采集的模型各层(包括注意力机制、前馈神经网络 (FFN)、通信和显存)性能数据,并对各种调度技术(静态批处理、动态批处理和 PD 分离服务)进行建模,推荐 PD 配置,在给定 GPU 预算内满足用户定义的 SLO,并最大化每个 GPU 的吞吐量,然后自动生成可无缝部署到 Dynamo 的后端配置。
AIConfigurator 支持命令行界面 (CLI) 和网页界面,初期支持 NVIDIA Hopper 上的 TensorRT-LLM。未来版本将陆续支持更多推理框架和 NVIDIA 硬件。
如何在不对 GPU 过度或不足配置的
情况下,持续满足推理 SLO
在今年 5 月的 0.2 版本中,我们推出了首版规划器 (Planner),专为生成式 AI 推理和 PD 分离设计的 GPU 自动扩展引擎。它能够通过监测 prefill 队列和 decode 内存使用情况,智能增减推理工作节点,最大化 GPU 利用率并最小化推理成本。
在 0.4 版本中,我们进一步完善了 Planner,新增基于 SLO 的自动扩展功能,使推理团队不仅能够降低成本,还能稳定地满足严格的性能指标,例如首 Token 延迟 (TTFT)、Token 间延迟 (ITL)。
与传统的响应式扩展系统不同,新的基于 SLO 的 Planner 采用前瞻性策略:
Planner 的与众不同之处在于能够预测输入 / 输出序列长度变化的影响,并在出现瓶颈前,主动扩展资源规模。
基于 SLO 的 Planner 使推理团队能够:
Planner 原生集成 Kubernetes,便于已经采用容器化基础设施的企业能够轻松部署 Dynamo,并使用 Planner 扩展其 AI 工作负载。此版本加入了对 vLLM 的支持,未来将持续支持更多推理框架。。
如何追踪实时推理可观察性指标
可观察性在大规模分布式推理环境中至关重要,使工程团队能够监测系统健康状况、诊断性能瓶颈并满足严格的 SLO,根据 SLO 的要求不断实时优化延迟、吞吐量和 GPU 利用率。
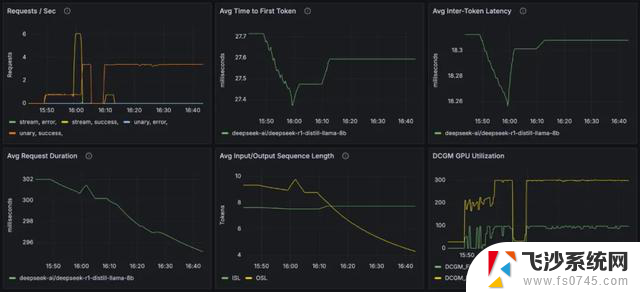
图 3. 显示 Dynamo 采集的关键性能指标的 Grafana 操作面板
在新发布的 Dynamo 0.4 中,事件、控制和数据平面的 Dynamo 工作节点和组件会输出关键的可观察性指标,包括:
这些指标通过开源的 Prometheus 工具采集,无需进行定制开发即可轻松集成到 Grafana 等开源监测和可观察性工具中。
本版本还包含一个 API,供工程团队和解决方案架构师定义和输出适配其服务环境的自定义指标,进一步提高了灵活性和可扩展性。
Dynamo 0.4 中的可观察性基础为后续版本奠定了基础,未来将引入更具细粒度、针对特定用例的指标,包括与 PD 分离相关的指标。
Dynamo 0.4 如何提升
系统弹性和早期故障检测能力
大规模部署前沿推理 MoE 模型需要支持数百 GPU 的多节点环境。在此类部署中,任何软硬件组件的故障(无论持续时间多短)都会中断整个系统的运行,并导致用户请求延迟或失败,进而影响业务运营,损害用户体验。
Dynamo 0.4 版本引入了实时请求重定向 (inflight request re-routing) 等容错和弹性功能。在之前的版本中,发送到离线 GPU 的请求会失败,并回退到推理栈上层或用户端,这会触发重试流程,即重复执行预处理步骤(如 Token 化和嵌入),浪费计算资源并增加延迟。经过此次更新,Dynamo 会在请求执行中动态重定向,保留中间计算结果并直接转发至在线 GPU,从而消除冗余工作。
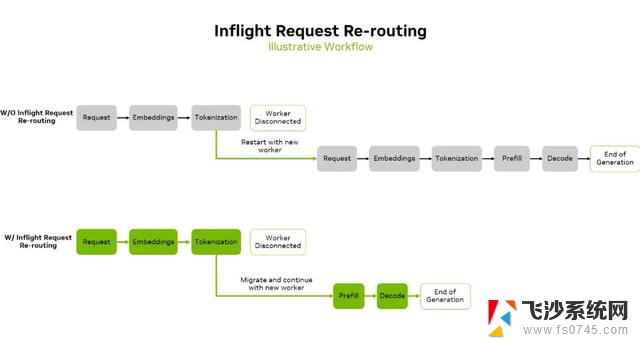
图 4. 生成过程中未启用(图片上半部)和启用(图片下半部)实时请求重定向的系统工作流差异示意图。
此外,此版本引入了更快的故障检测机制。在之前的版本中,etcd(Dynamo 控制平面中的关键组件)负责检测离线工作节点并向系统广播其状态。但这会引发几秒钟的延迟,在此期间请求仍可能被路由到离线工作节点。新版本在 Dynamo 智能路由器 (Smart Router) 中引入了早期故障检测功能,使其能够绕过 etcd 并响应关键健康信号,缩短了故障检测到恢复的时间窗口,显著减少了失败请求。
如何参与 Dynamo 开发者社区互动
欢迎您加入我们的 Discord 社区 (https://discord.gg/ZXRE8epz),来与其他开发者交流、分享反馈并获得实时支持。如果您对我们的开发方向感兴趣,请访问官方 Dynamo GitHub 开源资源库 (https://github.com/ai-dynamo/dynamo)。我们欢迎社区的贡献、问题反馈和想法。