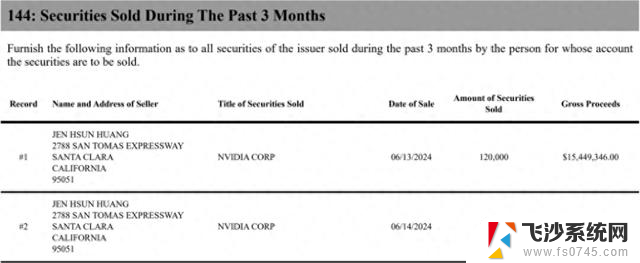
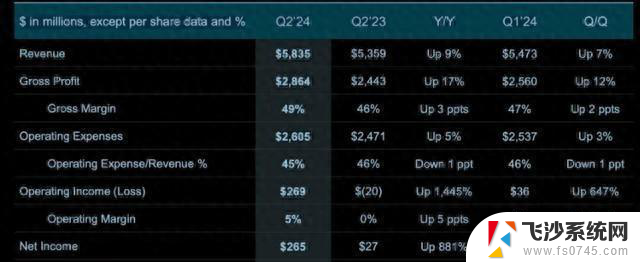
黄仁勋访谈揭秘:NVIDIA AI终局与下一代计算革命

黄仁勋回顾NVIDIA的起点,强调了30年前的一个关键洞察:“一个软件程序中,可能只有10%的代码完成了99%的处理,而这99%的处理可以并行完成。” 这一认知奠定了GPU的崛起。从最初为游戏提供逼真图形,到通过CUDA平台将并行计算能力开放给更广泛的科学计算领域,NVIDIA的每一步都踩在计算范式变革的节点上。
他将2012年的AlexNet视为AI领域的“寒武纪大爆发”,它证明了GPU在训练深度神经网络方面的巨大潜力。“我们当时自问,如果AI能做到这个程度,它究竟能走多远?它有潜力重塑整个计算机行业。” 黄仁勋坦言,正是这一判断,促使NVIDIA下定决心重塑整个计算堆栈,推出了DGX这样的AI超级计算机。
标题核心观点二:模型规模与数据驱动,AI能力无上限对于AI模型的发展趋势,黄仁勋坚信其可扩展性:“模型规模和数据量的持续增大,确实能让AI学到更多知识和更细致的特征,这是经过经验验证的。” 他认为,除非遇到物理、架构或数学上的根本性限制,否则AI的能力将持续提升。
更令人兴奋的是AI处理和转换不同数据模态的能力。“AI可以从文本到文本(总结、翻译),从文本到图像(生成),从图像到文本(描述),未来甚至可以从氨基酸序列到蛋白质结构,从蛋白质到文字描述其功能,或者从文字直接生成机器人的动作序列。” 这种跨模态的理解和生成能力,预示着AI应用的无限可能。
标题核心观点三:未来十年,AI应用科学的黄金时代黄仁勋预测:“过去十年是AI的基础科学研究阶段,未来十年将是AI的应用科学时代。” 这意味着AI将深度渗透到数字生物学、气候科技、农业、机器人、交通、物流优化乃至教育等各行各业。
他特别提到了“物理AI”(Physical AI),即机器人技术。NVIDIA正通过Omniverse(物理世界模拟与数字孪生平台)和Cosmos(世界基础模型,赋予机器人物理常识和理解能力)来加速这一进程。“未来,所有移动的东西都将是机器人化的,而且会很快到来。” 黄仁勋的愿景是,机器人将在Omniverse中学习,并在Cosmos的物理规则指导下,安全高效地服务于现实世界。
标题核心观点四:AI与芯片协同进化,能效是关键面对AI对算力的极致追求,黄仁勋强调:“能效是我们的首要任务。” 他以NVIDIA DGX举例,从2016年第一代交付给OpenAI,到如今的最新版本,AI计算的能效在8年内提升了10000倍。这种指数级的能效提升,是AI持续发展的关键保障。
在谈及芯片设计的哲学时,黄仁勋表示NVIDIA更倾向于构建灵活通用的计算架构,而非针对特定AI模型进行过度优化的专用芯片。“我们坚信创新将持续涌现,计算机科学和AI研究也远未终结。” 一个能够适应未来未知算法的平台,才能最大化创新潜力。
标题对比国内AI发展:应用场景广阔,核心技术仍需突破黄仁勋的蓝图无疑为全球AI发展指明了方向。反观国内,AI技术同样日新月异,大模型百花齐放(如百度的文心一言、阿里的通义千问等),应用场景加速落地,在智慧城市、自动驾驶、智能制造等领域展现出巨大活力。我们拥有海量数据、庞大市场和积极的政策支持,这些都是AI发展的沃土。
然而,在核心芯片、底层算法创新以及高端开发工具链等方面,我们与国际顶尖水平仍有差距。“自主可控”的呼声日益高涨,这既是挑战也是机遇。黄仁勋提及的“为自己打造AI导师”、“学习与AI高效互动(Prompt Engineering)”等建议,对国内从业者和学习者同样具有现实指导意义。下一代人必须思考:“我如何利用AI更好地完成我的工作?”
标题结语黄仁勋的愿景是构建一个AI无处不在、计算能力极大提升、人类生活因此变得更美好的未来。他领导下的NVIDIA,正以其强大的技术创新和生态构建能力,加速这一天的到来。
标题启发性问题:在这场由AI驱动的全球技术竞赛与产业变革中,除了在应用层面快速跟进。中国AI产业和从业者应如何在基础理论、核心技术和生态构建上实现“质”的突破,从而在全球AI版图中占据更主动、更有影响力的位置?欢迎在评论区分享你的见解。
作为一名开发者,英语学习也是很必要的,下面是收集的关键词:
Sequential Processing (顺序处理): 指计算机按照指令的先后顺序依次执行任务,一次只处理一个问题。Parallel Processing (并行处理): 指计算机同时执行多个任务或将一个大问题分解成许多小问题并行处理。CPU (Central Processing Unit 中央处理器): 通用处理器,擅长顺序处理和控制流程。GPU (Graphics Processing Unit 图形处理器): 最初设计用于处理计算机图形,但因其擅长并行处理,现在被广泛用于通用计算和AI加速。Cuda: NVIDIA推出的一个并行计算平台和API模型,允许开发者使用C、C++、Fortran等编程语言编写程序,利用GPU的并行计算能力。AlexNet: 2012年在ImageNet竞赛中取得巨大成功的深度卷积神经网络,使用NVIDIA GPU进行训练,标志着深度学习在图像识别领域的突破。Neural Network (神经网络): 一种模仿生物神经系统结构的计算模型,通过学习大量数据来识别模式和进行预测。Machine Learning (机器学习): 使计算机能够在没有明确编程的情况下从数据中学习的技术。Deep Learning (深度学习): 机器学习的一个子领域,使用包含多个处理层的深度神经网络进行学习。Computing Stack (计算堆栈): 指构成计算机系统各个层次的技术和软件,从底层硬件到操作系统、中间件和应用程序。DGX: NVIDIA推出的一系列专门用于AI和深度学习的超级计算机系统。Physical AI (物理AI): 指能够理解和与物理世界互动的人工智能,通常体现为各种形式的机器人。Omniverse: NVIDIA推出的一个用于3D协作和模拟的平台,可用于创建虚拟世界和训练机器人。Cosmos: 在访谈中被描述为一种“世界语言模型”或“世界模型”,用于为物理世界提供基础常识和理解。[其实是一个产品]Simulation (模拟): 在虚拟环境中模仿现实世界的过程,常用于训练和测试。Transformer: 一种流行的神经网络架构,尤其擅长处理序列数据,在自然语言处理(NLP)领域取得了巨大成功,也是许多当前AI模型的基础。Attention Mechanism (注意力机制): Transformer架构中的一个核心机制,允许模型在处理序列数据时关注输入序列中不同位置的重要性。Energy Efficiency (能源效率): 指在完成特定计算任务时所消耗的能量多少,是高性能计算和AI发展中的关键考虑因素。Digital Biology (数字生物学): 利用计算和AI来理解和模拟生物系统,例如理解分子和细胞的语言。Climate Science (气候科学): 利用计算和模拟来研究和预测气候变化。Digital Twin (数字孪生): 现实世界物体、系统或过程的虚拟表示,用于模拟、分析和优化。Superhuman (超人类): 指在特定任务或领域表现超出人类能力水平的AI或系统。Prompting AI (提示AI): 指向AI模型提供文本或数据输入(Prompt),以引导其生成期望的输出。